来源:小编 更新:2025-08-02 06:02:33
用手机看
你有没有想过,当你浏览网页时,那些网页上的信息是如何被系统快速抓取的呢?今天,就让我带你一探究竟,揭开系统前端抓取工具的神秘面纱!

想象你正在网上冲浪,突然发现了一个超级有趣的网站。你迫不及待地想要保存这些信息,但是手动复制粘贴太麻烦了。这时候,系统前端抓取工具就派上用场了。它就像一个勤劳的小蜜蜂,帮你从网页上快速抓取所需信息。
简单来说,系统前端抓取工具是一种自动化工具,它能够从网页上提取数据,并将其转换为可用的格式。这些工具广泛应用于数据挖掘、信息检索、网络爬虫等领域。
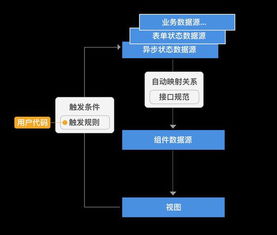
系统前端抓取工具的工作原理其实并不复杂。它主要分为以下几个步骤:
1. 网页解析:工具首先会对目标网页进行解析,提取出网页的结构信息,如HTML、CSS样式等。
2. 数据提取:根据解析出的结构信息,工具会定位到需要抓取的数据所在的位置,并将其提取出来。
3. 数据清洗:提取出的数据可能包含一些无关信息,如HTML、空格等。工具会对数据进行清洗,去除这些无关信息。
4. 数据存储:清洗后的数据会被存储到数据库或其他存储系统中,以便后续使用。
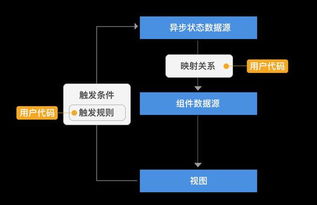
目前,市面上有很多种系统前端抓取工具,它们各有特点。以下是一些常见的类型:
1. 通用型抓取工具:这类工具适用于各种类型的网页,如静态网页、动态网页等。常见的有Beautiful Soup、Scrapy等。
2. 特定领域抓取工具:这类工具针对特定领域的网页进行抓取,如电商网站、新闻网站等。例如,E-commerce Data Extraction Tool、News Extractor等。
3. 可视化抓取工具:这类工具通过图形界面让用户直观地选择需要抓取的数据,操作简单。例如,Octoparse、WebHarvy等。
系统前端抓取工具的应用场景非常广泛,以下是一些典型的应用:
1. 数据挖掘:通过抓取大量网页数据,进行分析和挖掘,发现潜在的商业机会。
2. 信息检索:快速检索到所需信息,提高工作效率。
3. 网络爬虫:构建自己的搜索引擎,为用户提供更好的搜索体验。
4. 内容聚合:将分散在各个网站上的信息聚合在一起,方便用户阅读。
系统前端抓取工具在带来便利的同时,也存在一些优缺点。
1. 提高效率:自动化抓取数据,节省人力成本。
2. 准确性高:通过算法优化,提高数据抓取的准确性。
3. 灵活性强:适用于各种类型的网页,满足不同需求。
1. 可能侵犯版权:未经授权抓取他人网站数据,可能存在法律风险。
2. 抓取速度慢:面对大量数据,抓取速度可能较慢。
3. 难以应对反爬虫机制:一些网站设置了反爬虫机制,抓取难度较大。
系统前端抓取工具在现代社会中发挥着越来越重要的作用。了解其工作原理和应用场景,有助于我们更好地利用这些工具,提高工作效率。不过,在使用过程中,也要注意遵守相关法律法规,避免侵犯他人权益。让我们一起探索这个神秘的世界吧!

















